

Aprendizaje estadístico
Introducción al tema

Bienvenidos a mi primer tutorial de data science en este blog. Espero que este material les sea útil. Para estos tutoriales vamos a utilizar dos librerías de R, así que por favor corran lo siguiente en su consola de R:
install.packages("ISLR")
install.packages("MASS")Intro
En este tutorial vamos a cubrir lo siguiente:
¿Qué es el aprendizaje estadístico?
¿Para qué sirve el aprendizaje estadístico?
Introducción al análisis de datos
1 ¿Qué es el aprendizaje estadístico?
El aprendizaje estadístico (o machine learning, como prefieran llamarle) es una colección de herramientas usadas para entender la información que está contenida en los datos recolectados: o sea, separar la señal del ruido.
De manera general, dada una respuesta Y y P predictores (X_1, X_2, … , X_P), el objetivo del aprendizaje estadístico es encontrar una función f tal que
Y = f(X) + ϵDonde ϵ es un error aleatorio independiente de los predictores X y con media cero.
1.1 ¿Cómo encontramos f?
Los métodos para encontrar f se clasifican en dos grandes grupos: métodos parámetricos y métodos no paramétricos.
1.1.2 Métodos paramétricos
Los métodos paramétricos siguen un proceso de dos pasos:
Primero, tenemos que suponer alguna forma de
f. Por ejemplo, una suposición muy simple sería quefes una función lineal de los parámetrosX:f(X) = b_0 + b_1*X_1 + b_2*X_2 + … + b_p*X_pY el problema se reduce a estimar los
p+1coeficientesb_0, b_1, … , b_p.Después de seleccionar el modelo para
f, necesitamos un procedimiento que use los datos observados para entrenar nuestro modelo. En el caso del modelo lineal anterior, usaríamos comúnmente el método de mínimos cuadrados ordinarios, pero con cada modelo que vayamos cubriendo les voy a mostrar los procedimientos que pudiéramos usar para entrenar nuestra funciónf.
Los métodos paramétricos simplifican mucho el proceso del aprendizaje estadístico por que el problema se reduce a estimar un grupo de parámetros. También son muy útiles para interpretar el resultado del modelo, por que yo definí de antemano la forma de la función. Sin embargo, nada nos garantiza que la verdadera función f tenga la forma que nosotros elegimos, por lo que en algunos casos no nos van a dar un resultado muy bueno.
1.1.3 Métodos no paramétricos
Los métodos no paramétricos no hacen una suposición explícita sobre la forma de la función f. En vez de eso, buscan una aproximación a los puntos observados sin mucha variabilidad en su forma para evitar overfitting (esto es, que la función en vez de encontrar sólamente la señal encuentre la señal y el ruido). La ventaja con los métodos no paramétricos es que pueden ajustarse a muchísimas más formas de f, mientras que los métodos paramétricos me obligan a elegir una forma de f. Para poder usar métodos no paramétricos necesitamos una gran cantidad de datos (muchas más observaciones que para los métodos paramétricos) puesto que la cantidad de parámetros a utilizar es en general mucho mayor.
2 ¿Para qué sirve el aprendizaje estadístico?
Por ejemplo, imaginen que son consultores contratados por una compañía que usa 3 canales para hacerle pubilicidad a su producto: televisión, radio y periódico. Ellos no pueden controlar la venta del producto, pero sí pueden controlar cuánto gastan en cada canal de publicidad. Las ventas vs. el gasto en cada canal se ven de la siguiente manera para 200 locaciones distintas:

Parece ser que hay una relación fuerte entre gasto en publicidad de televisión y las ventas (a mayor gasto en TV, mayores ventas), lo mismo pero menos fuerte para radio y pareciera que la relación no es muy fuerte con el periódico. La idea del aprendizaje estadístico es llegar a una función que nos permita entender la relación entre Y (las ventas) y X (el gasto en los diferentes canales):
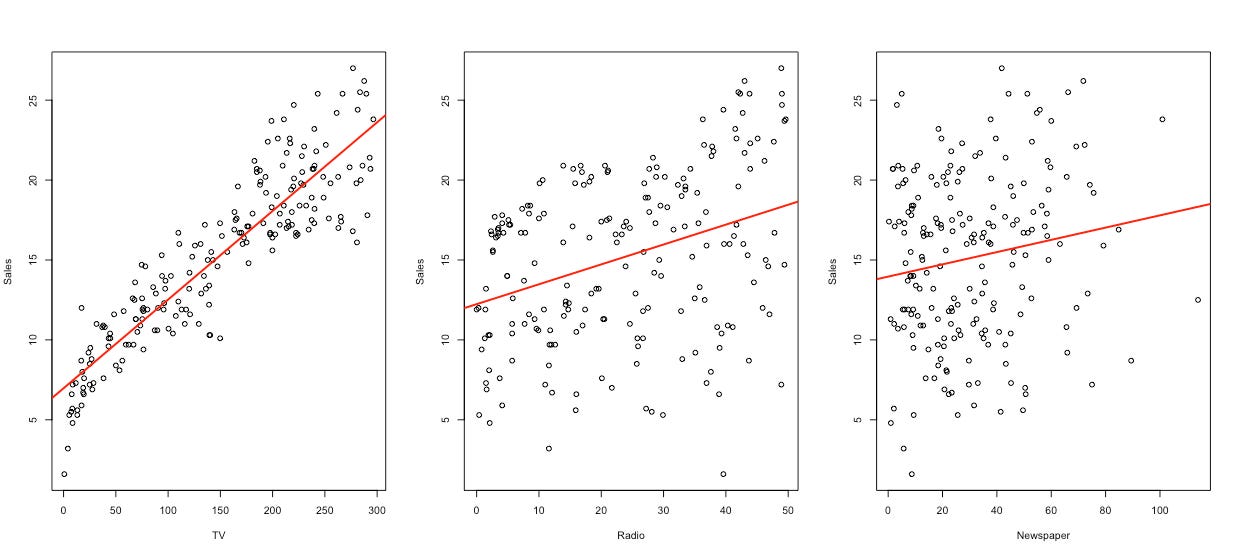
Conocer la función en la línea roja para cada uno de los canales nos permitiría tomar decisiones sobre que combinación de gasto en los diferentes canales nos dará la mayor cantidad de ventas posibles.
En general, vamos a utilizar estos métodos para hacer 2 cosas: predicciones o inferencia.
2.1 Predicciones
Como vimos en el ejemplo anterior, si encontramos la función f tal que:
Ventas = f(TV, Radio, Periódico) + ϵpodremos predecir cuánto vamos a vender dependiendo de cuánto gastamos en publicidad en cada canal. Nunca vamos a poder predecir exactamente por la existencia del término de error ϵ, pero sí podremos darnos una buena idea de los niveles generales que podemos esperar.
2.2 Inferencia
Quizá también estemos interesados en entender la relación entre los diferentes predictores X y la variable de respuesta Y. Esto nos va a poder permitir responder preguntas como las siguientes:
¿Cuáles predictores están relacionados con la respuesta? Pudiera ser el caso que no todas las variables
Xque tenemos disponibles tengan un efecto real en la respuestaY.¿Cuál es la relación entre la respuesta y cada predictor? Algunos predictores tendrán efectos positivos, otros pudieran tener efectos negativos, y otros incluso pudieran tener una relación con
Yque depende también de los niveles de otras variablesX.¿La relación entre las variables y la respuesta es lineal o es más complicada? En algunas situaciones, necesitaremos modelos más complicados que una simple ecuación lineal para encontrar una relación entre
XyYque sea de utilidad.
Para el ejemplo anterior, pudiéramos responder preguntas como:
¿Cuáles de estos canales de publicidad contribuyen a nuestras ventas?
¿Cuál canal en específico genera el mayor aumento en ventas?
¿Cuánto aumentan las ventas por cada peso adicional de promoción en radio?
3 Introducción al análisis de datos
Antes de empezar a aventar modelos por arriba y por abajo a un problema, es importante que entendamos los datos que estamos viendo y la relación entre las diferentes variables. Vamos a empezar todos los tutoriales siguientes con una sección introductoria al método que vamos a usar y después a la base de datos que utilizaremos para los ejemplos, pero creo que vendría bien ver un ejemplo de esto en este tutorial.
Para esto, vamos a utilizar el dataset College del paquete ISLR. Empecemos por cargarlo en nuestra sesión:
# 0. Limpiar la sesión
rm(list=ls())
if (names(dev.cur()) != "null device") {
dev.off()
}
cat("\014")
# 1. Cargar herramientas
library(ISLR)
# 2. Cargar el dataset College
data(College)
attach(College)La función attach() sirve para que R identifique el dataset College como el objeto de nuestro análisis posterior y podamos referirnos a sus diferentes variables directamente (e.g. en vez de usar College$Private podemos usar Private directamente y R entiende que nos referimos a la columna Private dentro de College). Y podemos ver ahora el dataset en nuestro ambiente:

El primer paso para familiarizarnos con los datos va a ser la función de ayuda de R:
?CollegeY vamos a ver el contenido y cada una de las variables en esta base de datos:
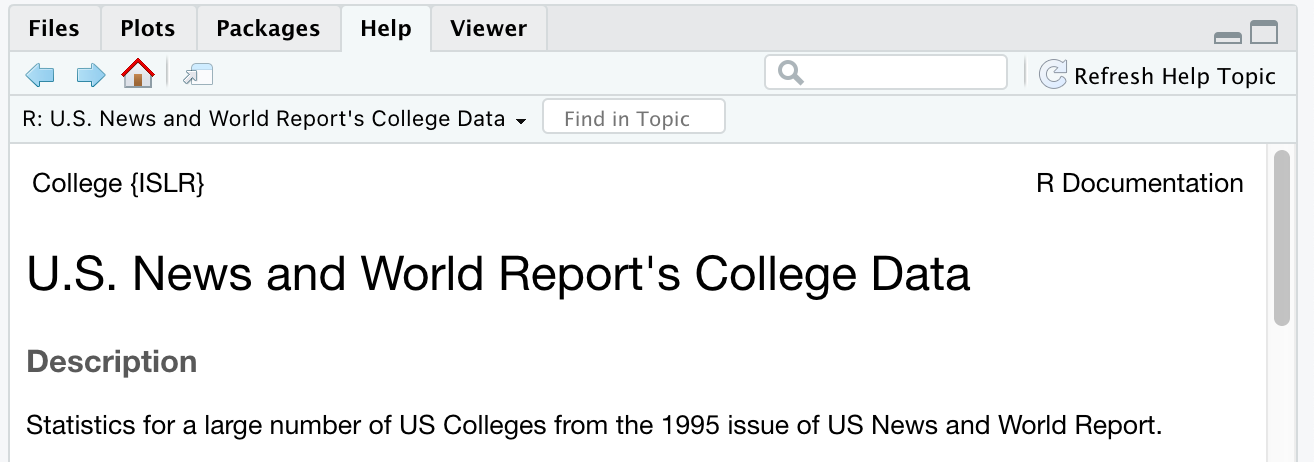
Vemos que está compuesto de 18 estadísticas de 777 universidades de Estados Unidos para 1995:
Private: indica si la universidad es privada o no
Apps: número de aplicaciones recibidas
Accept: número de aplicantes aceptados
Enroll: número de estudiantes nuevos
Top10perc: porcentaje de estudiantes que estuvieron en el 10% de su clase de preparatoria
Top25perc: porcentaje de estudiantes que estuvieron en el 25% de su clase de preparatoria
F.Undergrad: número de estudiantes de licenciatura de tiempo completo
P.Undergrad: número de estudiantes de licenciatura de medio tiempo
Outstate: colegiatura para estudiantes fuera del estado
Room.Board: costo de residencia de la universidad
Books: gasto estimado en libros
Personal: gasto personal estimado
PhD: porcentaje de profesores con doctorado
Terminal: porcentaje de profesores con grado académico terminal
S.F.Ratio: proporción de estudiantes a profesores
perc.alumni: porcentaje de exalumnos que donan a la universidad
Expend: gasto que hace la universidad por cada alumno
Grad.Rate: tasa de graduación
El siguiente paso sería ver el dataset directamente. Para esto, usamos el comando View() en la consola y podemos ver cada una de las entradas en la ventana de RStudio:
View(College)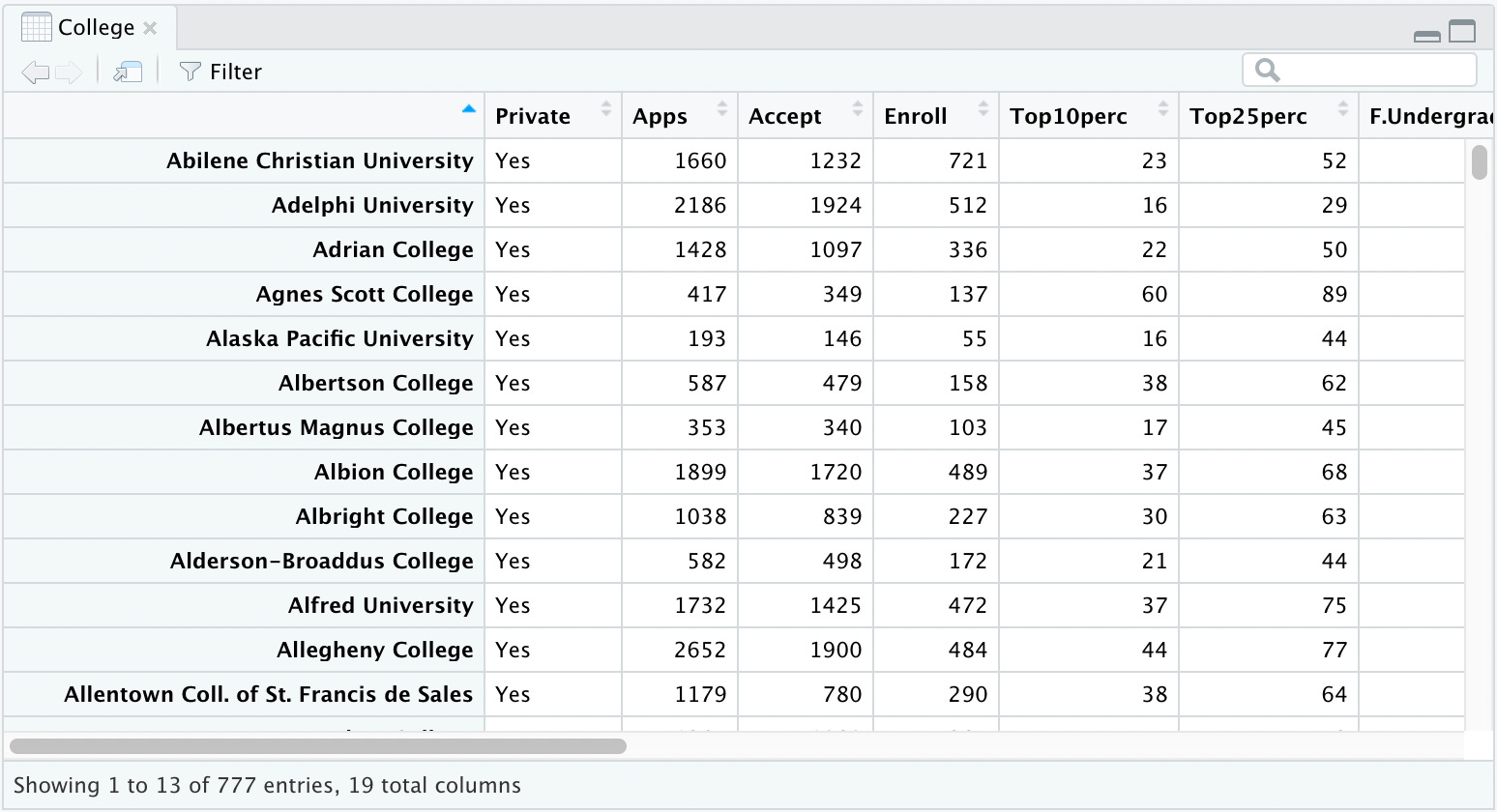
Sabiendo esto, podemos empezar a analizar los datos y responder preguntas como las siguientes:
¿Las colegiaturas son más caras en universidades privadas que en universidades públicas?
# 3. Colegiaturas públicas vs. privadas
boxplot(Outstate ~ Private,
main = "Colegiaturas en escuelas públicas vs privadas")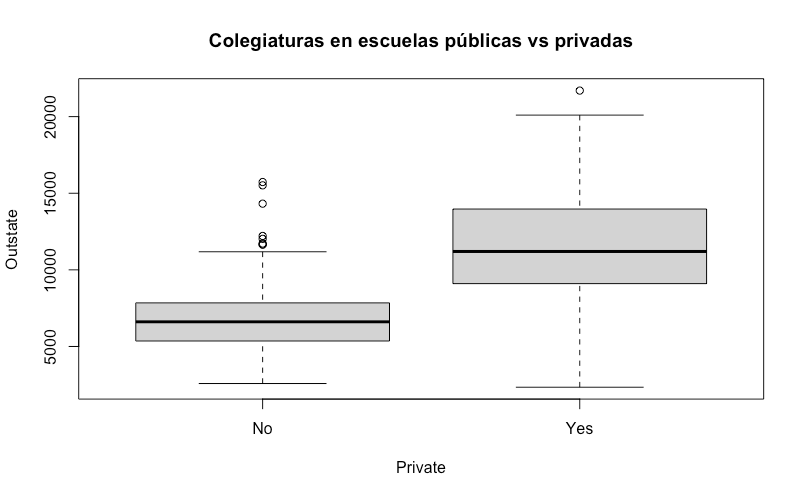
En general, esto es cierto, aunque vemos también que hay algunos valores atípicos en las universidades públicas que llegan a ser más caras que el tercer cuartil de las universidades privadas.
¿Las escuelas “elite”, definidas por que más del 50% de sus estudiantes vienen del mejor 10% de sus clases de preparatoria, son más caras que las universidades “no elite”?
# 3. Colegiaturas elite vs. no elite
Elite <- rep("No", nrow(College))
Elite[Top10perc > 50] <- "Yes"
Elite <- as.factor(Elite)
College$Elite <- Elite
boxplot(Outstate ~ Elite,
main = "Colegiaturas elite vs no elite")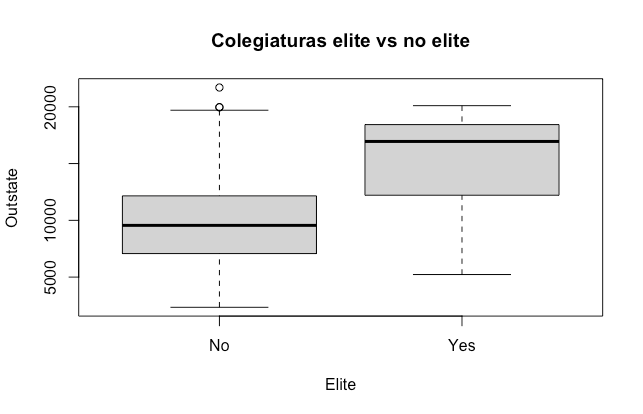
Aquí primero tenemos que crear nuestro factor Elite dependiendo de si la mayoría de los alumnos vienen del mejor 10% de su clase de preparatoria o no (Top10perc > 50). Después de incluir esta columna en el dataset original, vemos que efectivamente existe una relación entre la calidad de los estudiantes y la colegiatura de la escuela.
A mayor costo de colegiatura, ¿mayor el gasto por estudiante que realiza la universidad?
# 4. Colegiatura vs. gasto en estudiantes
plot(Outstate, Expend,
main = "Colegiatura vs gasto por estudiante")
abline(lm(Expend ~ Outstate), col = "red", lwd = 2)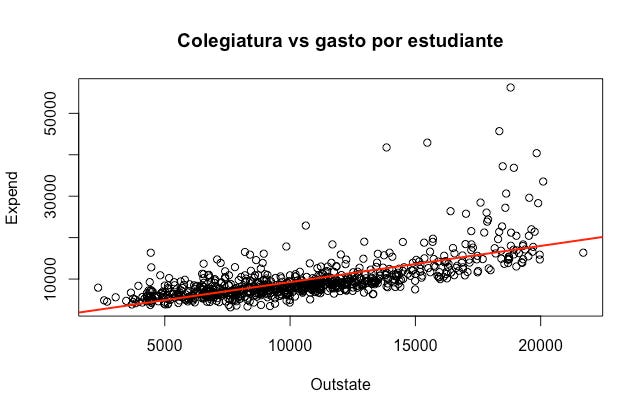
Por ahora no te preocupes por la función lm(), en tutoriales posteriores vamos a platicar de ella. Lo importante aquí es que, a mayor colegiatura, efectivamente incrementa el gasto que hace la universidad por cada estudiante. Lo interesante aquí es que hay más dispersión entre las universidades caras. Parece ser que hay muchas más universidades en este rango que están dispuestas a gastar más dinero en sus estudiantes del que reciben por colegiaturas. ¿De donde estará saliendo este dinero? ¿Será que estas universidades son las que reciben donaciones de un mayor porcentaje de sus exalumnos? Intenta responder esta última pregunta tú mismo.
Eso fue todo por hoy. Espero que este tutorial les haya servido. Si tienen cualquier duda o comentario pueden dejarlo en la sección de abajo. Si quieren compartir este blog con sus amigos y compañeros o suscribirse, les dejo los botones aquí:
Hasta el próximo tutorial!