
Regresión logística con 2 aplicaciones en finanzas
Regresión logística con 2 aplicaciones en finanzas

Intro
En este tutorial vamos a cubrir lo siguiente:
Introducción a los problemas de clasificación
¿Por qué no usamos regresión lineal?
Regresión logística
El modelo de regresión logística
Estimación de coeficientes
Haciendo predicciones
Regresión logística múltiple
Regresión logística en R
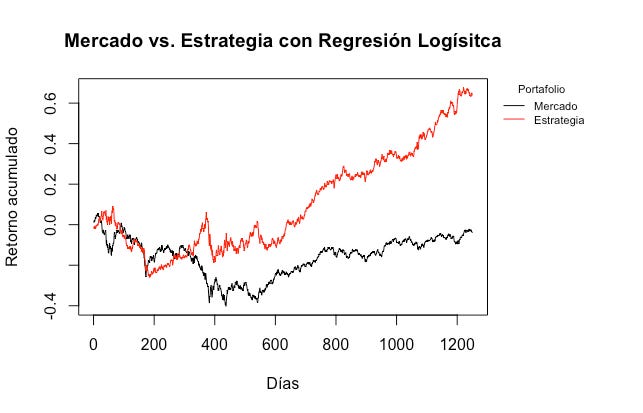
Vamos a explorar dos bases de datos diferentes. A lo largo del post vamos a analizar el dataset Default del paquete ISLR para crear un modelo de crédito. En los notebooks de Google Colab les voy a enseñar también a hacer una estrategia de inversión usando regresión logística con buenos resultados:
1 Introducción a los problemas de clasificación
En el tutorial de regresión lineal nuestro objetivo era predecir una variable cuantitativa, el nivel de ventas en función de la inversión hecha en cada canal específico de publicidad. ¿Cómo le hacemos entonces cuando queremos predecir una variable cualitativa? Por ejemplo, en los siguientes casos:
Una persona va al doctor con un conjunto de síntomas X que pudieran apuntar a 3 trastornos diferentes. ¿Cuál de estas 3 enfermedades es la que sufre nuestro paciente?
Un banco necesita determinar si una transacción realizada en su servicio de banca en línea es fraudulenta o no dados el IP del usuario, su historial de transacción, la ubicación geográfica del dispositivo en el que se realizó, etc.
Dada una base de datos con información genética de pacientes con y sin una enfermedad específica, una compañía de biotecnología quiere identificar que mutaciones específicas causan esta enfermedad.
Para estos casos tenemos, igual que en el caso de la regresión lineal, una matriz X de n renglones (observaciones) y p columnas (predictores). Nuestra respuesta Y contiene la clase a la que cada observación i pertenece.
En este tutorial vamos a utilizar el dataset Default del paquete ISLR como ejemplo de un caso de clasificación. Este dataset contiene 10,000 registros de personas con una tarjeta de crédito y las siguientes columnas:
default: un factor con niveles “Yes” o “No” indicando si el cliente está en mora o nostudent: un factor con niveles “Yes” o “No” indicando si el cliente es un estudiante o nobalance: saldo promedio que el cliente mantiene en su tarjeta de crédito después de hacer su pago mensualincome: ingreso del cliente
Veamos cómo se relacionan estos datos
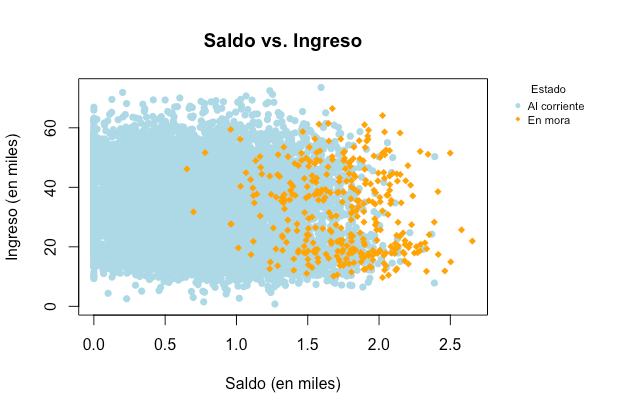

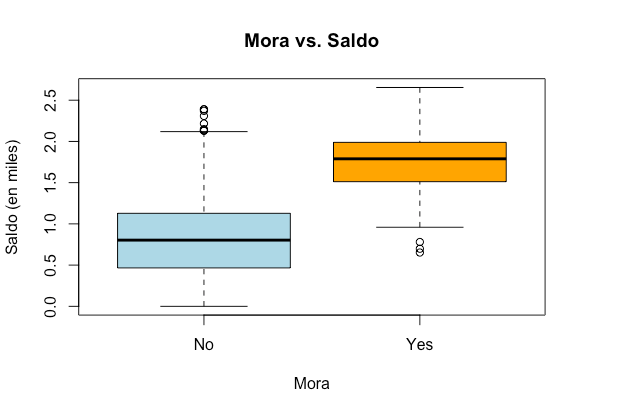
Podemos ver que los clientes morosos tienden a tener un saldo mayor en su tarjeta de crédito. En este tutorial vamos a calcular la probabilidad de que un cliente caiga en mora dado su ingreso, el saldo en su tarjeta y si es estudiante o no.
1.1 ¿Por qué no usamos regresión lineal?
En el tutorial de regresión lineal vimos cómo usar variables dummy para representar predictores cualitativos. Ahora quizá se estén preguntando, ¿por qué no simplemente usamos una variable dummy para la respuesta y resolvemos el problema con regresión lineal? Veamos a continuación que podría suceder.
Si tenemos una respuesta con dos niveles, como la del modelo de crédito, podemos crear una variable dummy para la respuesta de la siguiente forma:

Hacer una regresión lineal de esta manera convierte la respuesta en P(Y|X), o sea, la probabilidad de que el cliente caerá en mora (Y) dadas sus características (X). Veamos a continuación cómo se vería este modelo con los datos de nuestro dataset usando como predictor el saldo del cliente:
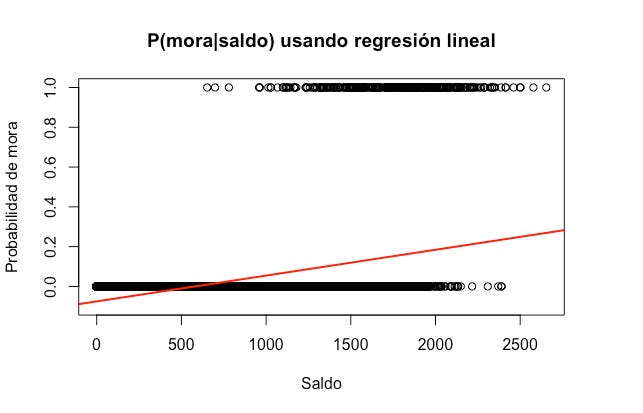
Vemos que algunas de nuestras predicciones caen fuera del intervalo [0, 1], lo que dificulta su interpretación (¿qué quiere decir “probabilidad de mora negativa”?). Aún en este caso podríamos usar este modelo de alguna manera, pero el problema se complica cuando la respuesta tiene más de 2 niveles.
Supongamos que ahora intentamos predecir la condición de un paciente en la sala de emergencias dados sus síntomas. Los síntomas que presenta se pueden dar debido a tres causas: un infarto cerebral, una sobredósis o un ataque epiléptico. Si acomodamos nuestra respuesta de la siguiente manera:

estamos implícitamente creando un orden en la respuesta. En este caso, la diferencia entre estar sufriendo un infarto cerebral y una sobredósis es la misma que la diferencia entre estar sufriendo una sobredósis y un ataque epiléptico. En la práctica no hay razón por la que esto deba ser así. Si escogiera un orden diferente, por ejemplo:

de nuevo estoy introduciendo un orden en la respuesta aunque ahora la relación entre ellas es completamente diferente. Cada una de estas opciones produciría modelos diferentes y, en consecuencia, predicciones diferentes para la misma matriz de predictores X. Por esta razón, es mejor abstenernos de usar regresión lineal para resolver problemas de clasificación.
2 Regresión logística
La regresión logística es un modelo que nos permite determinar la probabilidad de que la observación i pertenece a alguna categoría en particular. Para nuestro caso, P(mora|saldo) usando regresión logística tendrá la siguiente forma:
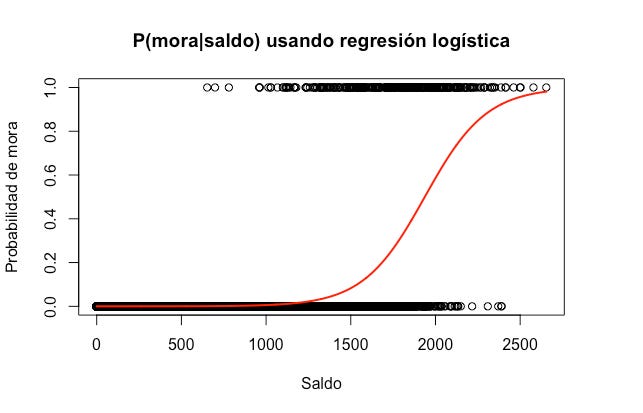
Noten como ya no hay predicciones fuera del intervalo [0, 1].
2.1 El modelo de regresión logística
Este modelo se basa en descrubrir la relación entre P(X) = P(Y = 1|X) y X. Si usaramos regresión lineal, esta probabilidad va a estar dada por:

Sin embargo, aquí vamos a tener el problema de tener predicciones fuera del intervalo [0, 1], lo que no tiene sentido. Para evitar este problema, usamos la función logística:

Esta función siempre va a producir una gráfica en forma de S entre 0 y 1 como la de la sección anterior, dándonos predicciones razonables de la probabilidad que estamos intentando modelar.
Con un poco de manipulación algebráica, podemos ver que:

o sea que un incremento unitario en X no aumenta linealmente la probabilidad P(X) por β_1 sino la función logit (también llamada log-odds en este contexto) de nuestro problema. Esto es muy importante de tener en cuenta al momento de interpretar los coeficientes de la regresión logística.
2.2 Estimación de coeficientes
Para encontrar los coeficientes β_0 y β_1, usamos el procedimiento de estimación por máxima verosimilitud. El procedimiento consiste en buscar estimados de estos dos parámetros que hagan que la predicción de probabilidad P(X) resulte lo más cercana a su estado observado Y. En nuestro caso, deberá ser cercano a 1 para los individuos en mora y cercano a 0 para los que están al corriente con su tarjeta de crédito. Matemáticamente, buscamos maximizar la siguiente función:

En nuestro caso, los coeficientes que encontramos son los siguientes:

El coeficiente del saldo es positivo, por lo que concluímos que un incremento en el saldo resulta en mayor probabilidad de mora (recordemos que no aumenta por 0.0055 la probabilidad directamente sino las log-odds). Los valores p son muy chicos, por lo que concluimos que nuestro modelo es estadísticamente significativo.
Si queremos usar una variable cualitativa como nuestro predictor (por ejemplo, la columna que indica si el cliente es estudiante o no en nuestro caso), sólo debemos transformar este predictor en una variable dummy. En nuestro caso, obtenemos la siguiente relación:

Lo que nos hace concluir que los estudiantes tienden a tener una mayor probabilidad de mora que los clientes que no son estudiantes.
El intercepto no nos dice nada de interés en la regresión logística, así que podemos ignorarlo en ambos casos.
2.3 Haciendo predicciones
Para predecir la probabilidad de mora utilizando la regresión logística, sólo hay que sustituir valores en nuestra ecuación de P(X). Por ejemplo, para un cliente con un saldo de $1,000:

Lo cual resulta en una predicción muy baja: menos del 1% de probabilidad. Sin embargo, cuando el saldo incrementa a $2,000 vemos que la probabilidad es mayor al 50%:

Con el caso de un estudiante vs. no estudiante, vemos lo siguiente:


2.4 Regresión logística múltiple
Igual que con la regresión lineal, podemos usar más de un predictor al mismo tiempo para la regresión logística. En el caso donde querramos usar p predictores en nuestro modelo, la ecuación P(X) tendrá la siguiente forma:

Y de igual manera usamos el procedimiento de estimación por máxima verosimilitud para obtener los p+1 coeficientes que necesitamos.
Si usamos las tres variables (balance, income y student) en nuestro modelo, obtenemos lo siguiente:

Aquí notamos algo interesante. Cuando utilizamos el predictor de estudiante por sí sólo, el efecto era positivo. Ahora que utilizamos los 3 predictores, resulta que el efecto es negativo. ¿Cómo puede ser esto? Analicemos un poco más este predictor:
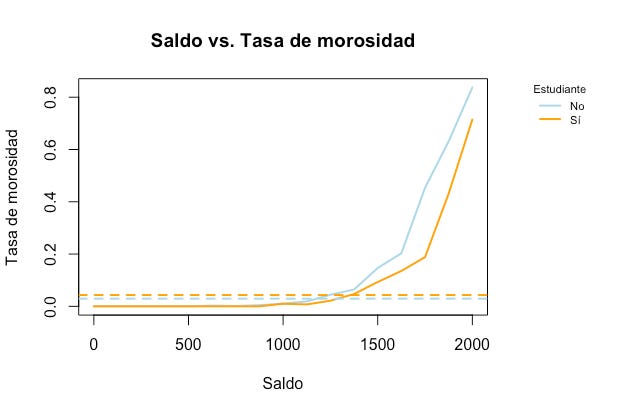
El coeficiente negativo indica que, para un nivel dado de saldo, es menos probable que un estudiante caiga en mora (la línea sólida azul siempre está por encima de la naranja). Sin embargo, la tasa de morosidad de estudiantes calculada sobre todos los saldos es mayor a la de los no estudiantes (la línea punteada naranja está por encima de la línea punteada azul) y por eso es que usando sólo student como predictor terminamos con un coeficiente positivo. ¿Cómo podemos explicar esta aparente paradoja?

He aquí el culpable. El saldo de los estudiantes es mayor al de los no estudiantes, y anteriormente ya habíamos determinado que a mayor saldo, mayor es la probabilidad de caer en mora. Los predictores student y balance están correlacionados. O sea que, aunque un estudiante individual tenga menor probabilidad de caer en mora contra un cliente con el mismo saldo que no es estudiante, los estudiantes en general tienden a tener saldos mayores y, por lo tanto, son más propensos a caer en mora como grupo. Este es un punto importante a tener en cuenta, y es un ejemplo de lo que llamamos factor de confusión.
Para predecir entonces la probabilidad de caer en mora con nuestro modelo de regresión logística múltiple para un estudiante con un ingreso de $40,000 y saldo de $1,500, hacemos lo siguiente:

Para un no estudiante con mismo ingreso y saldo tenemos:

Noten que usamos 40 en vez de 40,000 como ingreso por que al calcular nuestro modelo representamos el ingreso en miles.
3 Regresión logística en R
Aquí les dejo los notebooks de Google Colab con el modelo de crédito que creamos y la estrategia de inversión usando regresión logística:
Eso fue todo por hoy. Si tienen cualquier duda o comentario pueden dejarlo en la sección de abajo. Si quieren compartir este blog con sus amigos y compañeros o suscribirse, les dejo los botones aquí:
Hasta el próximo tutorial!